About Me
Welcome to my personal homepage!
My name is Tongxu Luo, a junior PhD student at Chinese University of Hong Kong, Shenzhen. I received my bachelor degree in Computer Science and Technology from USTB in 2025.
I have a strong interest in all topics about LLMs and am actively exploring and expanding the boundaries of current LLM technology. My recent research mainly focuses on Test-Time Training and Large Reasoning Models. So far, I have published papers in conferences such as NeurIPS, CoLM and EMNLP, with a total of Google Scholar citations ().
News
- 2025.7 🎉 Our paper “E2-RAG: Towards Editable Efficient RAG by Editing Compressed KV Caches” has been accepted to CoLM 2025!
- 2025.5 📢 Our new paper “Learning from Peers in Reasoning Models” is now available on arXiv!
- 2024.9 🎉 Our paper “Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training” has been accepted to NeurIPS 2024 Spotlight!
- 2024.9 🎉 Our paper “Unlocking Continual Learning Abilities in Language Models” has been accepted to EMNLP 2024 Findings!
- 2024.9 🎉 Our paper “Neeko: Leveraging Dynamic LoRA for Efficient Multi-Character Role-Playing Agent” has been accepted to EMNLP 2024 Main!
Selected Publications
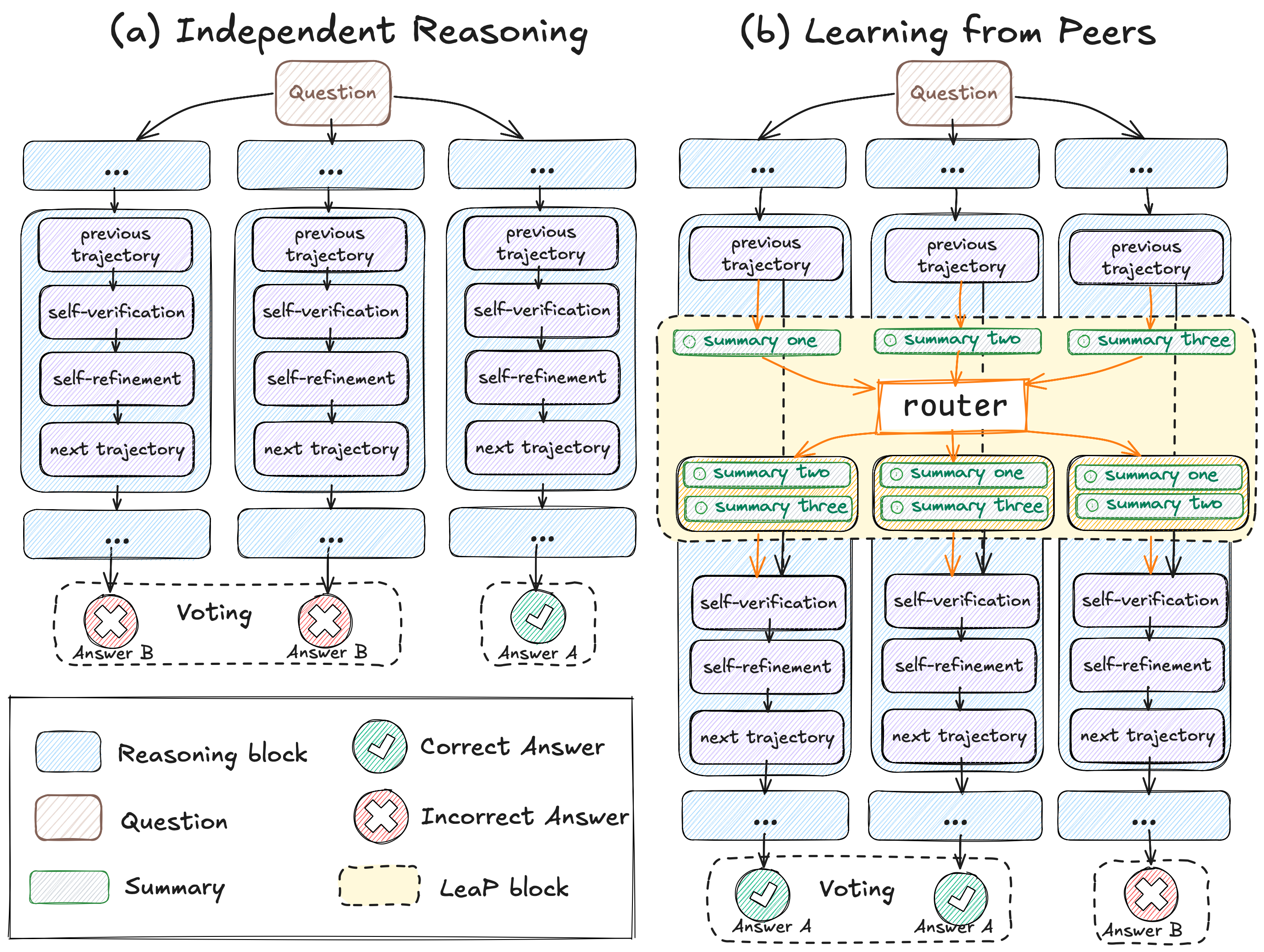
[Arxiv Preprint] Learning from Peers in Reasoning Models
We find Large Reasoning Models often get stuck when they start reasoning incorrectly (the "Prefix Dominance Trap"). To address this, we propose LeaP (Learning from Peers), a method where parallel reasoning paths share intermediate summaries to learn from each other and self-correct during inference.


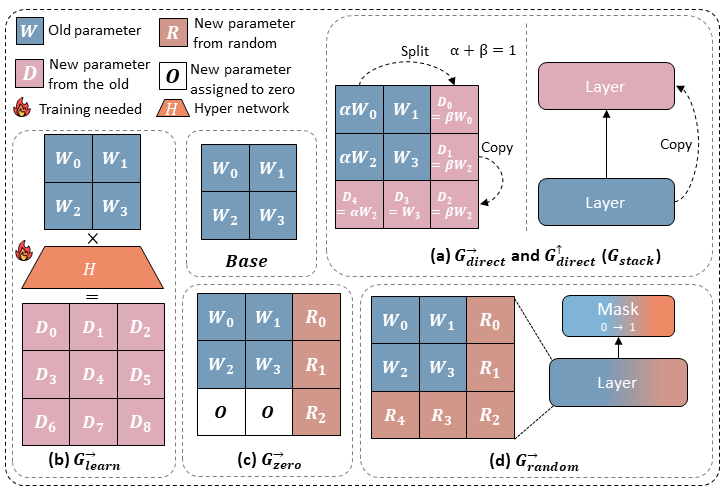
[NeruIPS 2024 Spotlight] Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
We investigate model growth techniques for efficient LLM pre-training, identifying a depthwise stacking operator that significantly accelerates training and improves performance by leveraging smaller models to build larger ones, while also providing systematic evaluation and guidelines for its application.
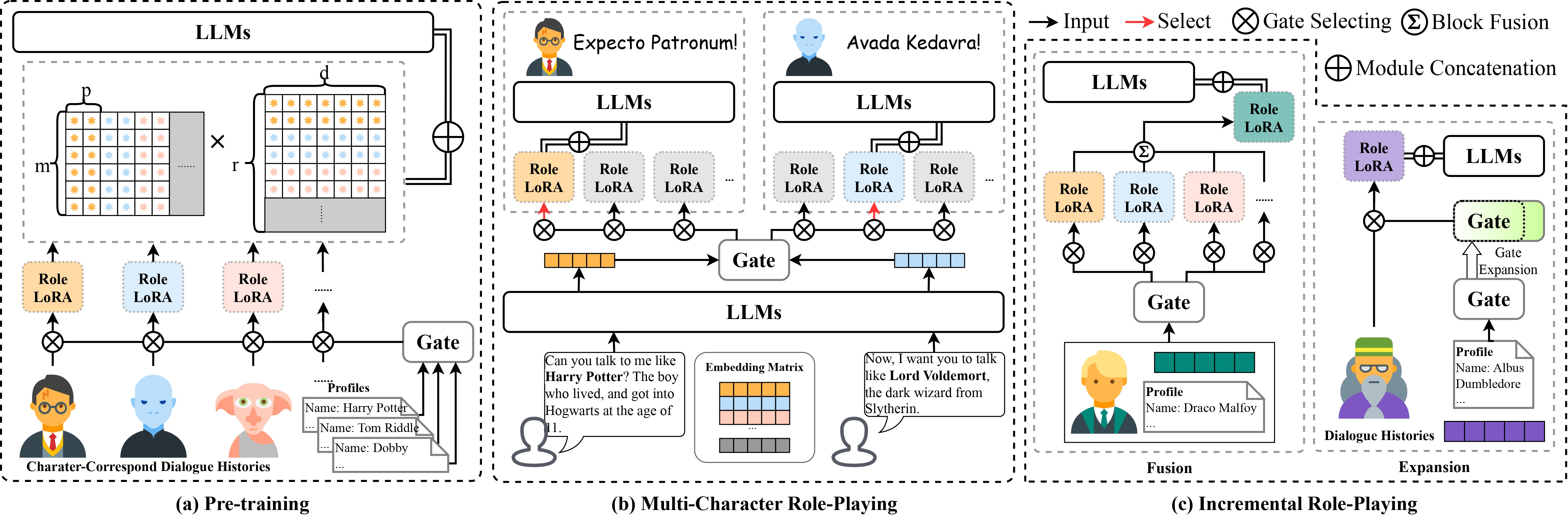
[EMNLP 2024 Main] Neeko: Leveraging Dynamic LoRA for Efficient Multi-Character Role-Playing Agent
We present Neeko, an innovative framework designed for efficient multiple characters imitation. Unlike existing methods, Neeko employs a dynamic low-rank adapter (LoRA) strategy, enabling it to adapt seamlessly to diverse characters.
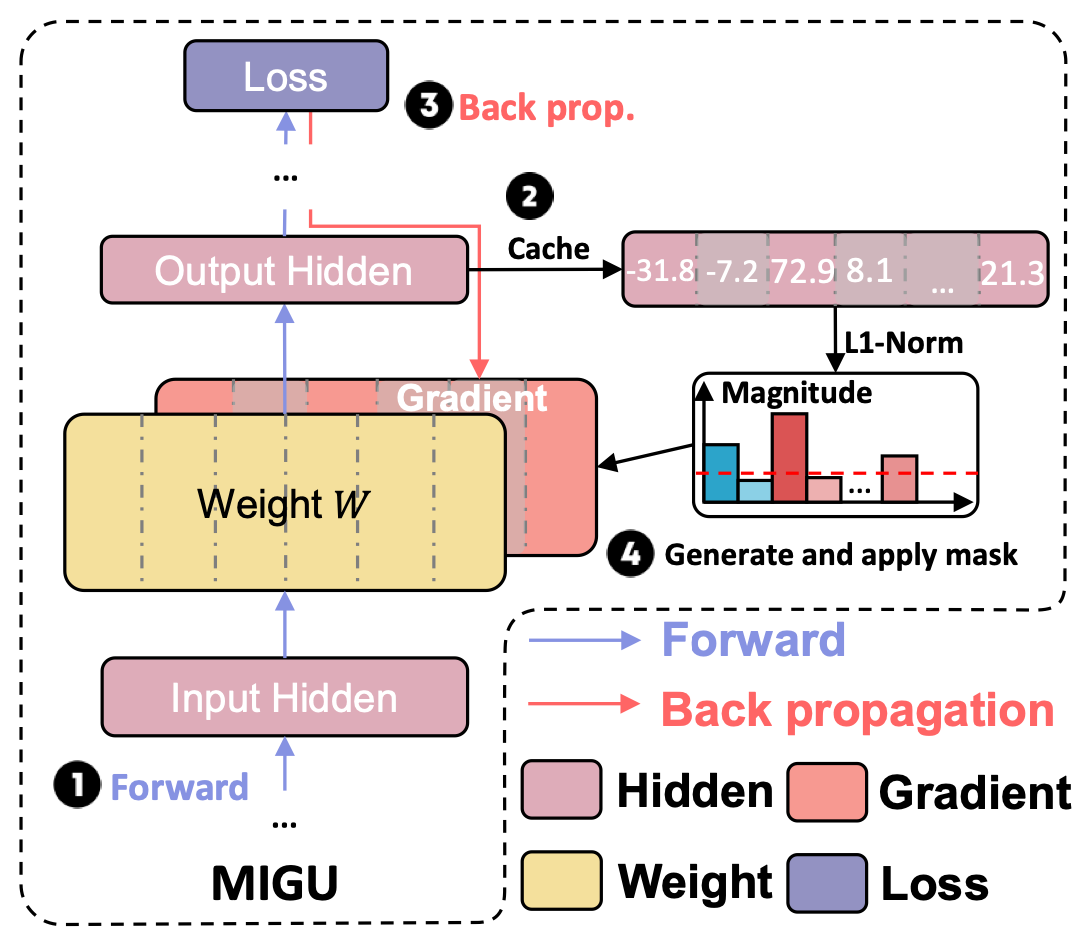
[EMNLP 2024 Findings] Unlocking Continual Learning Abilities in Language Models
We introduce MIGU, a novel rehearsal-free and task-label-free continual learning method for language models that combats catastrophic forgetting by only updating model parameters exhibiting large output magnitudes in their linear layers.
Awards
- 2023.10🏆 I was awarded the National Scholarship during the second academic year!
Contact Me
I am seeking collaborators, and I'm particularly looking for undergraduate students with strong coding abilities and (senior) PhD students who possess unique insights.
If you are interested in my work, please feel free to contact me! 🤗
